Day 28
Math 216: Statistical Thinking
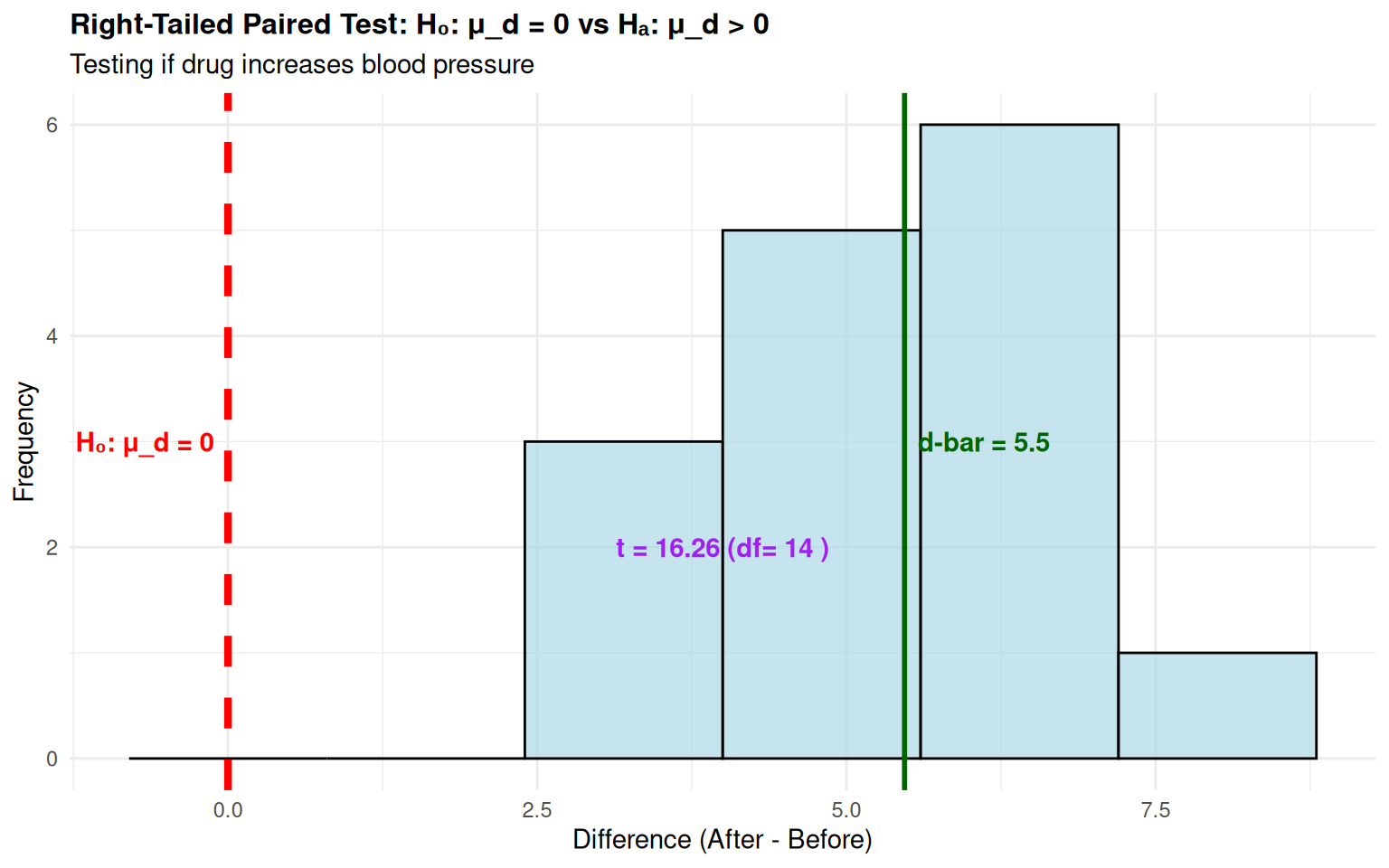
Worked Example 2: Two-Tailed Paired t-Test
Context: Educational study testing if teaching method affects test scores (n=12)
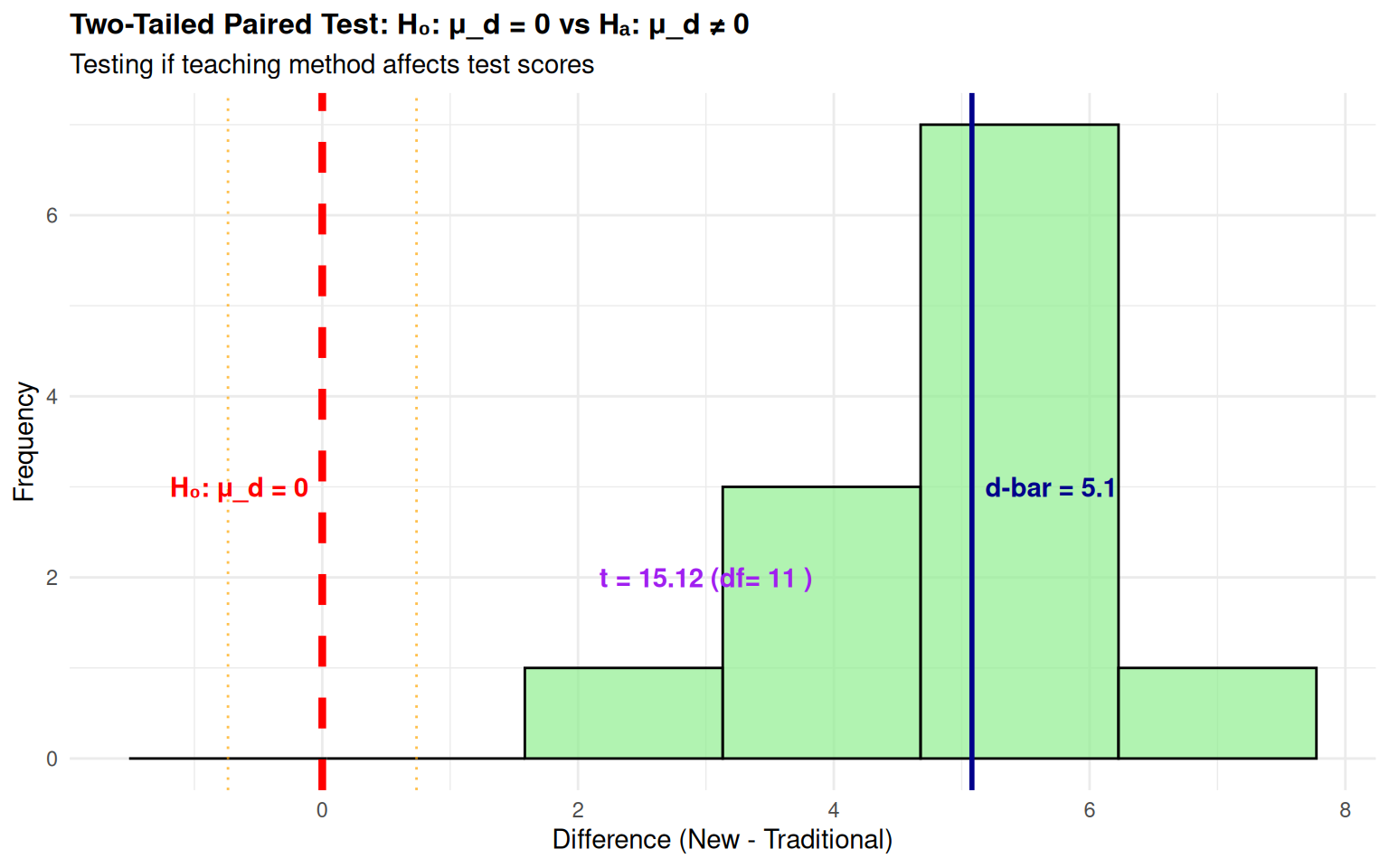
- \(H_0\): \(\mu_d = 0\) (no difference between methods)
- \(H_a\): \(\mu_d \neq 0\) (methods differ)
- Sample: n=12 paired measurements
- Test Statistic: \[t = \frac{5.08}{1.16/\sqrt{12}} = 15.12\]
- Critical Value: \(|t_{0.025, 11}| = 2.201\)
- Decision: Since \(|15.12| > 2.201\), reject \(H_0\)
- Conclusion: Strong evidence that teaching methods differ
Diagnostic Plots and R Code
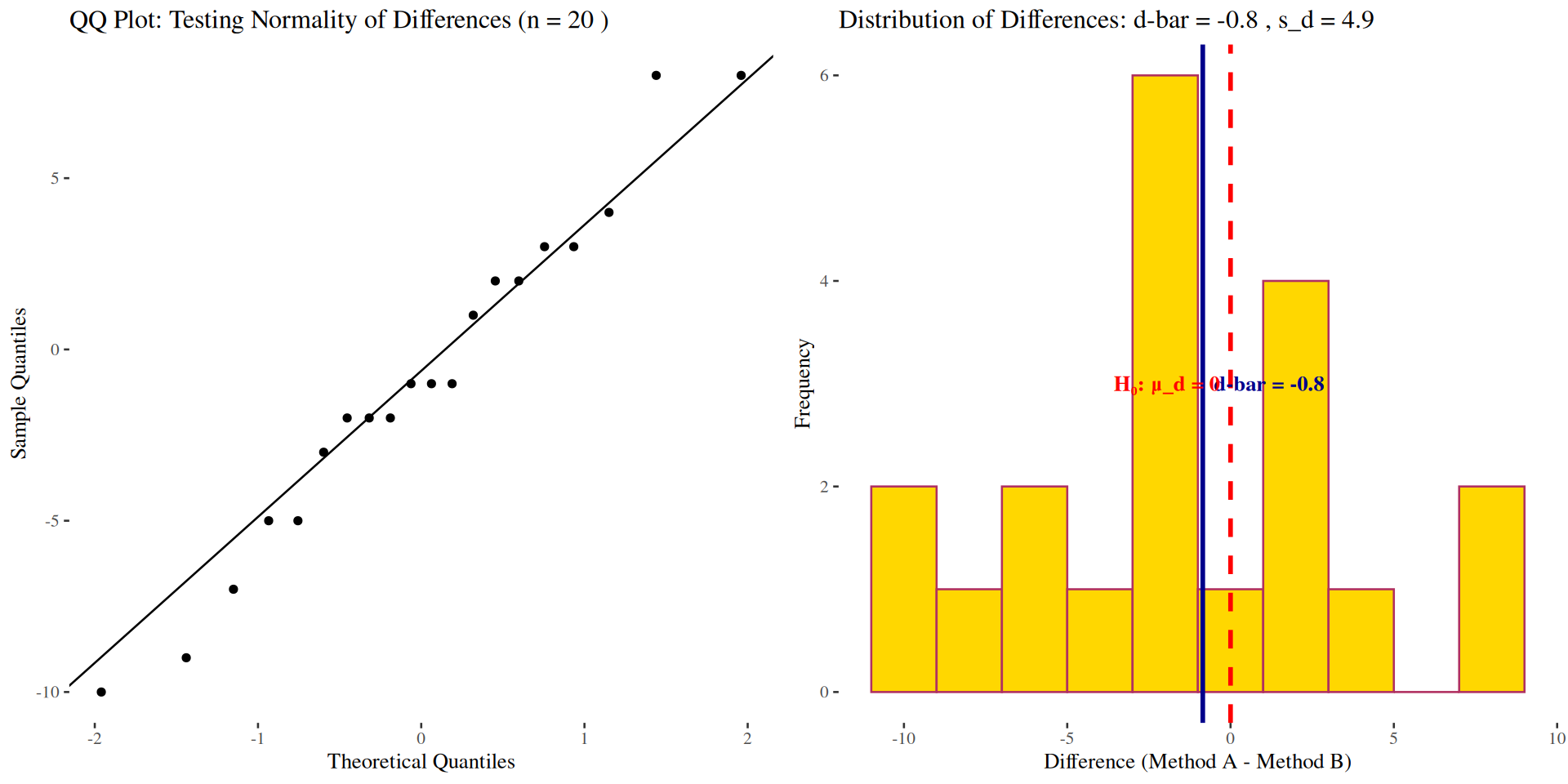
# Define the scores for Method A and Method B
methodA <- c(85, 88, 90, 92, 91, 89, 93, 95, 96, 97, 98,
99, 100, 101, 102, 103, 104, 105, 106, 107)
methodB <- c(83, 89, 87, 84, 92, 90, 85, 91, 98, 94, 100,
101, 99, 111, 111, 106, 109, 103, 111, 114)
# Calculate differences
differences <- methodA - methodB
# Generate a QQ plot for normality check
qq_norm <- ggplot(data = tibble(differences), aes(sample = differences)) +
stat_qq() + stat_qq_line() +
ggtitle("QQ Plot of Differences")
# Generate a histogram for normality check
histogram <- ggplot(data = as.data.frame(differences), aes(x = differences)) +
geom_histogram(bins = 10, color = "maroon", fill = "gold") +
ggtitle("Histogram of Differences")