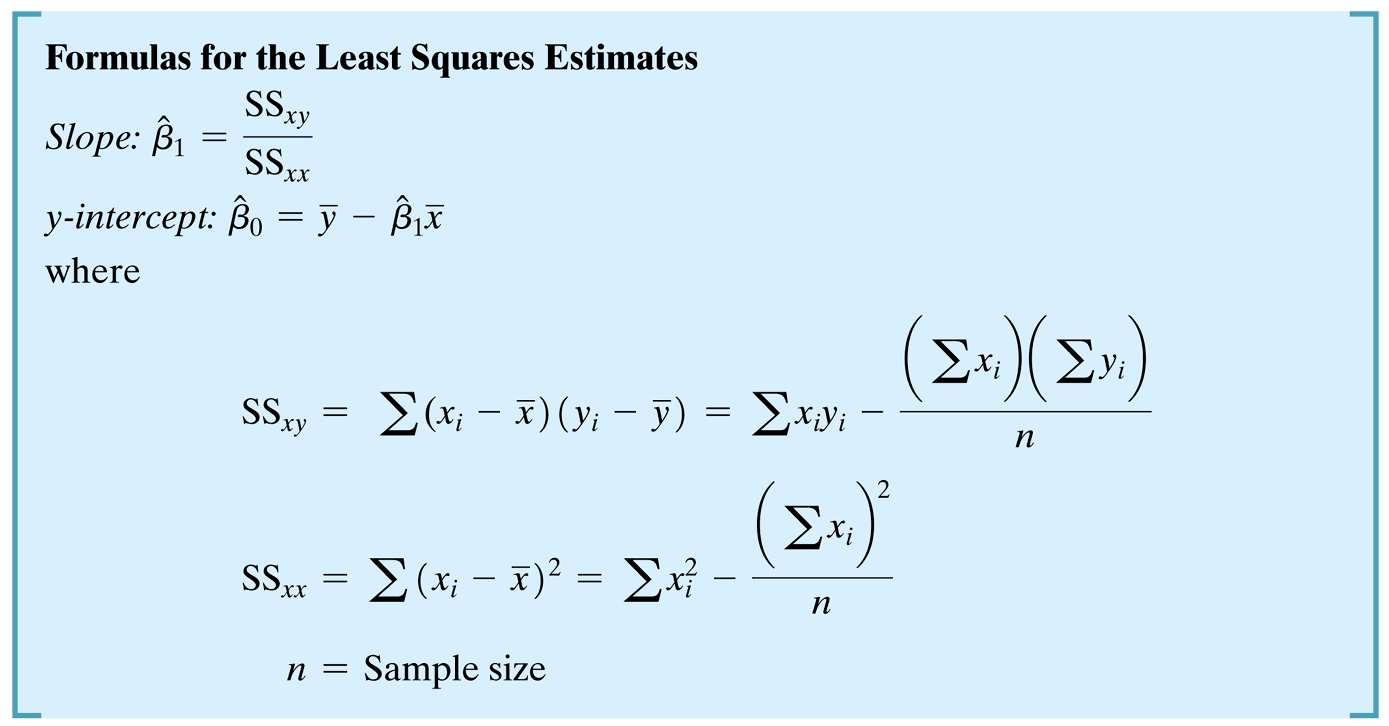%%{init: {"theme": "base", "themeVariables": {"fontSize": "24px", "fontFamily": "Arial", "lineColor": "#333"}}}%%
flowchart LR
%% --- Styling Definitions ---
classDef start fill:#FFFACD,stroke:#FF8C00,stroke-width:2px,color:#000
classDef step fill:#E6F3FF,stroke:#1E88E5,stroke-width:2px,color:#000
classDef action fill:#E8F5E9,stroke:#43A047,stroke-width:2px,color:#000
classDef endStyle fill:#FFEBEE,stroke:#E53935,stroke-width:2px,color:#000
%% --- Five-Step Process ---
A([Start: Research Question]):::start
B["Step 1: Hypothesize<br/>E(y) = β₀ + β₁x"]:::step
C["Step 2: Estimate<br/>Find b₀, b₁ via Least Squares"]:::step
D["Step 3: Specify Distribution<br/>ε ~ N(0, σ²)"]:::step
E["Step 4: Evaluate Model<br/>Test H₀: β₁ = 0"]:::step
F["Step 5: Use Model<br/>Prediction & Estimation"]:::step
G["Validated Model<br/>Ready for Application"]:::endStyle
%% --- Connections ---
A --> B
B --> C
C --> D
D --> E
E --> F
F --> G
%% --- Visual Polish ---
linkStyle default stroke:#333,stroke-width:2px;
Day 36
Math 216: Statistical Thinking
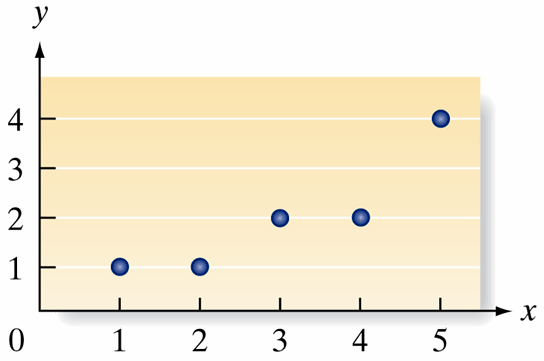
Real-World Example: Drug Reaction Time Study
Research Question: How does drug concentration affect reaction time?
- Scenario: Medical researchers want to predict reaction time \(y\) based on drug percentage \(x\) in bloodstream
- Data: Collected from five subjects (simplified for learning)
- Goal: Build a model to understand and predict drug effects
Key Insight: Even simple experiments can reveal important relationships - and help us understand the regression process step by step!

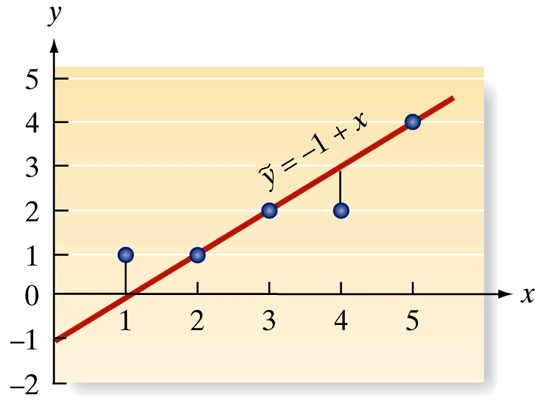
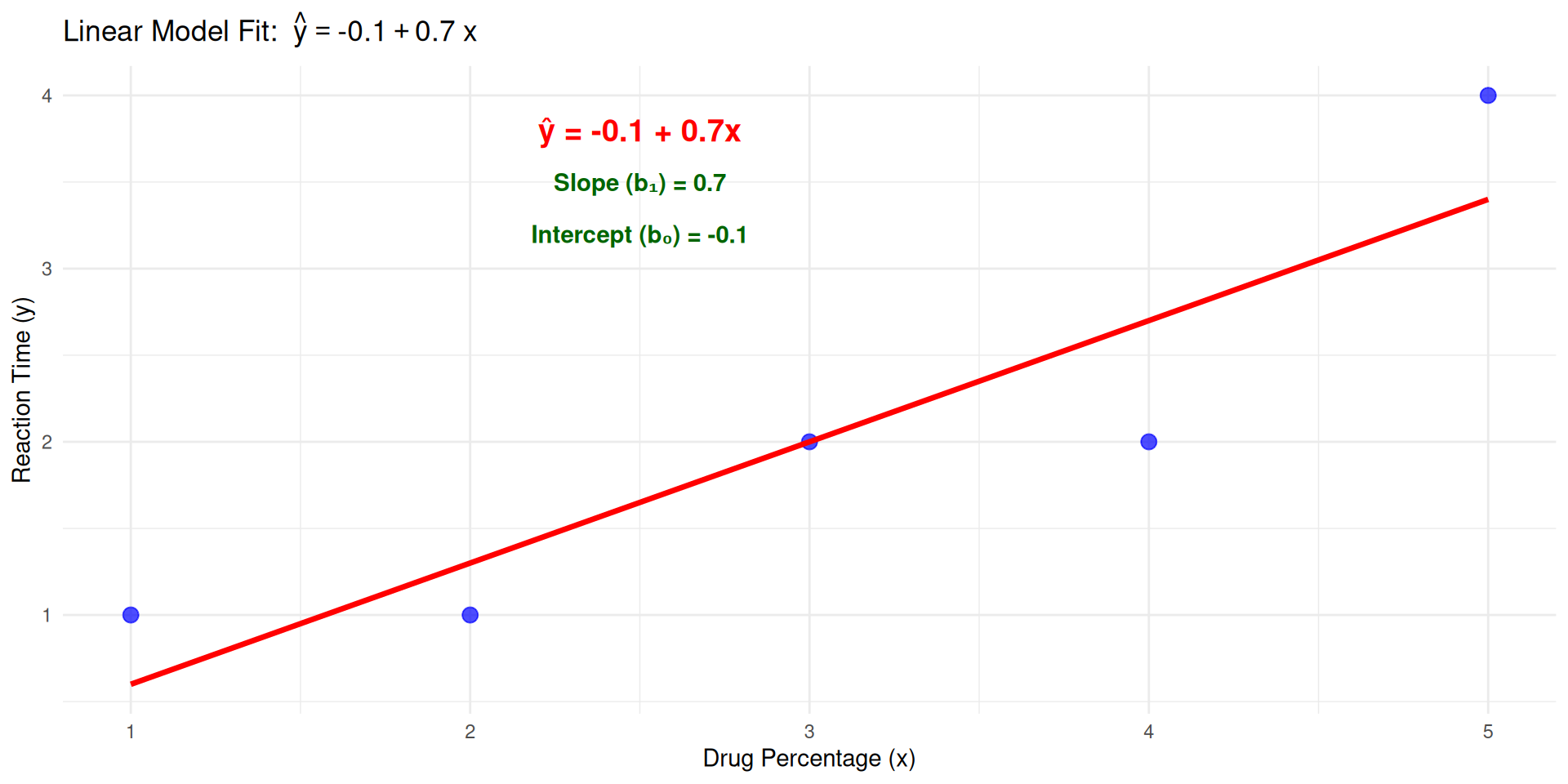
Step 2: Estimate Model Parameters from Sample Data
Key Question: How do we find the “best” values for \(\beta_0\) and \(\beta_1\) using our sample data?
- Challenge: Use our five observations to estimate the unknown \(y\)-intercept \(\beta_0\) and slope \(\beta_1\)
- Method: Least squares estimation - finding the line that minimizes prediction errors
- Goal: Transform our hypothesis into concrete parameter estimates